In the software world, the word "scale" is one of the most important terms because I believe that understanding scale is what separates senior developers from juniors. Of course, some developers overuse this word and end up making the code more complicated for scaling scenarios they will never face in the next 10 years. But when developing large-scale applications, you must be prepared for it.
Scaling isn’t always about handling a large number of requests. Sometimes it’s about managing huge amounts of storage, memory, or CPU computations. The key is to identify where the bottleneck is.
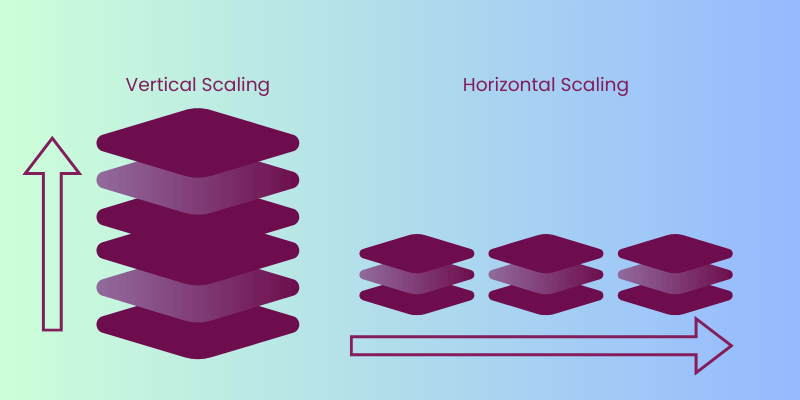
A pattern I’ve noticed in many environments is that developers are very familiar with vertical scaling. Sometimes, they rely on it so much that the answer to any slow API or unresponsive request is simply “increase the memory or CPU.” To be honest, I believe this approach leads to a huge, inefficient codebase and massive infrastructure costs. Plus, vertical scaling only lets you handle larger requests or operations, not a huge number of operations.
The other type of scaling is horizontal scaling. Instead of increasing memory or CPU, you increase the number of application instances and use a load balancer to distribute requests between them. Kubernetes even has HPA (Horizontal Pod Autoscaling), which automatically adds instances when needed!
The point is, you must consider autoscaling in your code. You can’t just autoscale every application—you need to follow certain patterns to avoid issues and errors when deploying a multi-instance application. The simplest rule is that you cannot keep state in your applications, because instances are constantly scaling up and down, and you will lose that state. In this blog post, we’re going to explore some key considerations for making applications HPA-ready.
First, we’ll do a quick intro on how Kubernetes autoscaling works. Then, we’ll dive into key topics like state management, database handling, concurrency, jobs and background tasks, and scaling metrics.
K8s Horizontal Pod Autoscaler
The Horizontal Pod Autoscaler (HPA) automatically adjusts the number of pod replicas in a Deployment, StatefulSet, or ReplicaSet based on observed metrics (like CPU, memory, or custom metrics).
This ensures your application has enough pods to handle load without wasting resources.
Metrics Collection
- The HPA relies on the Kubernetes Metrics API.
- By default, metrics come from the Metrics Server, which collects CPU and memory usage from kubelets.
- You can also use custom metrics (via Prometheus Adapter, OpenTelemetry, etc.).
- Target Metric & UtilizationYou define a metric in the HPA spec, e.g., “keep average CPU at 50%”.For example:
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-app
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50Autoscaling Algorithm
- Every 15 seconds (default), the HPA controller: "desiredReplicas = currentReplicas * ( currentMetricValue / targetMetricValue )"
Example:desiredReplicas = 4 * (100 / 50) = 8
→ HPA scales from 4 → 8 pods.- Fetches metrics (e.g., CPU usage).
- Computes desired replicas using this formula:
- Current Pods: 4
- Target CPU: 50%
- Current Avg CPU: 100%
Scaling Behavior
- Scale Up happens quickly (to handle spikes).
- Scale Down happens slowly (default stabilization window is 5 minutes to prevent flapping).
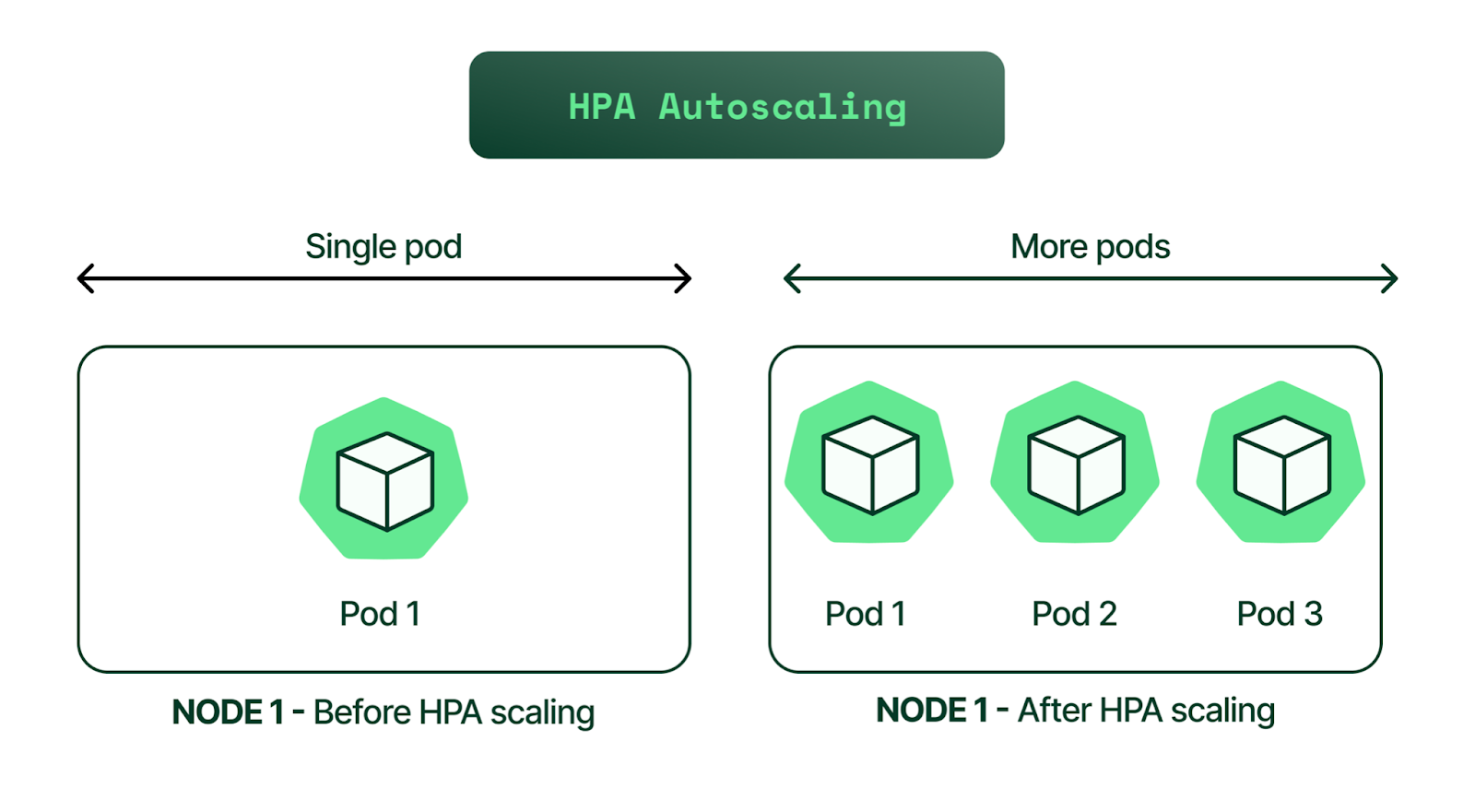
Sounds great—this handles all the scaling! But what do we need to do in our code?
No In App States
As you can see, Kubernetes will kill and redeploy app instances. So what happens if we keep state in the app? A user might have just logged in, and suddenly, for no reason, they have to type their password again and rebuild their shopping cart—hoping their instance is still alive during the process.
The golden rule—and the most important one: no state in the application.
You must keep all state outside of the application—sessions, files, caches, queues, and so on. You can use a database (PostgreSQL, Mongo, etc.), distributed caches like Redis, or any other external service. That way, when one instance is killed, another can pick up right where things left off.
In short: don’t keep data locally, and be ready to die at any moment!
Database & Connection Handling
In a single-instance application, we usually create a bunch of database connections and reuse them during the request lifecycle, or we set up connection pools. That’s a good approach—but with HPA things work a bit differently. For example, if we forget to close a connection, after 100 cycles of killing and redeploying the app, we might hit the database connection limit (PostgreSQL’s default max connections is 100). Or another case: Kubernetes spins up a lot of instances, and each one creates its own connections, leading to database overload. Keep in mind, each PostgreSQL connection takes about 60–100 MB of memory!
You should always use connection pooling libraries, set proper max connection limits, and have a cleanup strategy to close any unused database connections.
You also need to be careful with retry policies. Imagine your database is running slow due to load or a network hiccup—suddenly, multiple instances have failing requests. If all of them retry at the same time, a flood of requests can hit the database at once and… BOOM, the DB goes down!
To handle this, you can use an exponential retry policy. Instead of retrying immediately, wait a little before the next attempt. If it still fails, wait even longer before retrying again.
Example: wait 100ms → 200ms → 400ms → 800ms, etc.
Or use jitter (a random delay). If all instances wait exactly 100ms, they’ll still end up retrying together. Instead, add randomness—for example, 200ms ± random(50ms).
And don’t forget to limit retries—you don’t want to keep retrying a request that has already failed 20 times. If it hasn’t worked by then, it’s not going to!
Handling Concurrency
Many of us have faced concurrency issues before, and we know how to handle them. In a single-instance application, you only need to take care of data inside your own instance. You can usually manage this with locks or serializables. But in a multi-instance setup, things get trickier—what if two instances try to do the same job? Or both try to change some external state at the same time?
The first and most important rule is to make operations idempotent. This means that running the same operation twice should have the same effect as running it once.
for example
- Good:
markOrderAsPaid(orderID)— calling it twice doesn’t double-charge. - Bad:
chargeCustomer(orderID)— calling it twice charges twice.
Sometimes, message queues using an “At Least Once” delivery strategy will send the same message to multiple workers, so they all try to do the same job. To handle this, you can use deduplication keys—for example, store a “job ID processed” in Redis or your database.
In really harsh cases, you can use distributed locks—but only when absolutely necessary, because they can significantly impact performance.
Background Jobs & Async tasks
When your app scales horizontally, it’s easy to forget that background tasks scale too. Suddenly, every replica might be running the same cron job, sending duplicate emails, or processing the same queue item multiple times
The problem: “N replicas = N jobs”
- Imagine you have a cron job inside your web app that cleans old sessions every hour.
- On 1 replica → runs once per hour.
- On 10 replicas → runs 10 times per hour.
- Same goes for tasks like:
- Sending scheduled emails.
- Generating daily reports.
- Batch data cleanups.
- These tasks are usually meant to run once, but scale multiplies them.
To handle this, one approach is to separate your worker jobs and logic into worker pods and worker pools. Another option is to implement leader election between instances, so that only one instance takes the jobs and runs them.
Scaling Metrics & Application Design
Horizontal auto-scaling works by adding or removing replicas based on metrics. But not all metrics tell the full story. If your app isn’t designed to expose the right signals, scaling might not actually solve your problems.
HPA & basic metrics aren’t enough
- Kubernetes HPA or cloud autoscalers often use CPU or memory usage.
- Problem: your app may not be CPU-heavy but could still struggle under load.
- Example: a high-latency database call or slow queue processing doesn’t show up in CPU usage.
- Scaling on CPU alone might add more pods without fixing the real bottleneck.
Application-level metrics
To scale effectively, your app should expose metrics that reflect real workload:
- Requests in flight / pending HTTP requests.
- Queue length (number of unprocessed jobs in Kafka, RabbitMQ, or DB table).
- Error rates or retries.
- Latency / response times.
These are called custom or business-level metrics. They help the scaler decide when you actually need more instances.
If you use the wrong metrics, you might end up wasting resources without achieving the desired outcome.
Conclusion
Scaling an application horizontally is more than just spinning up more instances—it requires careful planning and design. From keeping your applications stateless, handling database connections wisely, and designing idempotent operations, to managing background jobs and exposing the right metrics, each consideration plays a critical role in making your app truly HPA-ready.
Remember, autoscaling can’t fix poor application design. It’s a tool that amplifies what’s already there. By following these best practices, you ensure that your app can handle growing workloads efficiently, avoid common pitfalls, and make the most of Kubernetes’ powerful Horizontal Pod Autoscaler. In the end, thoughtful architecture and proper scaling strategies are what separate scalable, reliable applications from fragile ones.