
Logs are one of the fundamental pillars of application monitoring and observability. They are essential tools for debugging and troubleshooting—when something goes wrong, the first thing a software engineer typically does is check the logs. As a DevOps engineer, one of my key responsibilities is to make logs more accessible, helping teams quickly find the information they need and ensuring all relevant data is available for troubleshooting. In this post, I’ll show you how to collect application logs from a Kubernetes cluster and display them in Grafana.
Let’s break down the pieces of this puzzle. We’ll be using the OpenTelemetry (Otel) Collector, Loki, and Grafana. First, let’s take a closer look at each tool to understand what it does and how it can help us.
Grafana
Grafana is a well-known tool, so I don’t need to introduce it in detail. It’s a powerful platform for visualizing data in various formats, and it allows you to create dashboards and generate reports based on that data.
Loki
Loki is a log storage system, and as it describes itself, it's "like Prometheus but for logs." While there are other popular log storage backends, like Elasticsearch, I preferred Loki for my use case. In this case, I know exactly what I'm deploying and the log formats involved. Elasticsearch is a full-text search engine, and performing full-text indexing requires a lot of resources and effort. Additionally, maintaining and configuring Elasticsearch can be complicated. On the other hand, Loki only indexes logs based on labels. Honestly, why index everything when you don’t have a use case for it? With Loki, we can focus on creating meaningful labels and indexing logs based on those labels to fetch the right logs for our specific needs.
Otel Collector
The OpenTelemetry (Otel) Collector is my favorite tool among all observability tools. It’s essentially a data pipeline that allows you to collect various data formats, process them, convert them, and export them in other formats. As part of the OpenTelemetry project, the Otel Collector simplifies your setup by eliminating the need to manage multiple collectors and backends for each datatype and format. It’s lightweight, stable, and, in most cases, you don’t need to modify your code to use it. The Otel Collector can become your single source of truth for collecting logs, metrics, and traces.
What we are going to build?
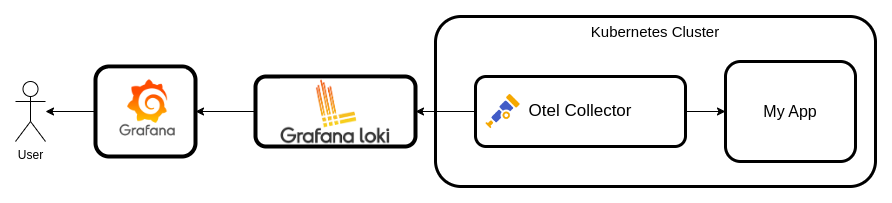
In this guide, we’ll deploy a simple dummy application that generates logs. We’ll then collect those logs using the Otel Collector, add labels, process them, and store them in Loki. Finally, we’ll display the relevant output using Grafana. To set everything up, we’ll use Minikube as our Kubernetes cluster.
The first step is to locate the logs. To do this, let's SSH into the Minikube node and find where the logs are stored. You can do this by running:
minikube sshOnce inside the Minikube node, run:
docker psThis command will show you the containers running on your cluster. Since it's a fresh cluster, you'll likely see Kubernetes system containers like k8s-api-server, controller-manager, and others.
Now, navigate to the directory where pod logs are stored:
cd /var/logs/pods && lsHere, you’ll find a folder for each pod. If you navigate into one of these folders, you’ll see files with numeric names. The Container Runtime Interface (CRI) creates one file for each pod restart, so the largest number represents the count of pod restarts. If you inspect one of these files using the cat command, you’ll see the logs in JSON format.
Now, let’s create a dummy application that generates random logs and deploy it in our cluster. This application will help us simulate a real-world scenario for collecting and managing logs. Below is the Go code for the application:
package main
import (
"log"
"math/rand"
"time"
)
func main() {
// Seed random number generator
rand.Seed(time.Now().UnixNano())
// Define log messages
messages := []string{
"Operation completed successfully!",
"Error: Unable to connect to the database.",
"Success: Data processed correctly.",
"Error: Unexpected end of input.",
"Success: User login was successful.",
"Error: Failed to write to the file system.",
}
// Infinite loop to log random messages
for {
message := messages[rand.Intn(len(messages))]
if rand.Intn(2) == 0 {
log.Printf("[INFO] %s", message)
} else {
log.Printf("[ERROR] %s", message)
}
time.Sleep(time.Duration(rand.Intn(3000)+1000) * time.Millisecond)
}
}
After creating the dummy application, we’ll need a Dockerfile to build a Docker image for it. This image will allow us to deploy the application in our Kubernetes cluster. Here’s the Dockerfile:
FROM golang:1.23-alpine3.21 as builder
# Set the working directory
WORKDIR /app
# Copy the Go source code
COPY random_logger.go /app/
# Build the Go application
RUN go mod init random_logger && go build -o random_logger random_logger.go
# Set the entrypoint to the binary
ENTRYPOINT ["/app/random_logger"]Finally, we’ll create a Kubernetes deployment to deploy our dummy application in the cluster. The deployment ensures that our application runs as a pod within the Kubernetes environment. Here’s the deployment YAML:
apiVersion: apps/v1
kind: Deployment
metadata:
name: random-logger
labels:
app: random-logger
spec:
replicas: 2
selector:
matchLabels:
app: random-logger
template:
metadata:
labels:
app: random-logger
spec:
containers:
- name: random-logger
image: mhadij/random_logger
Now that our application is deployed, let’s move on to setting up our monitoring stack. As mentioned earlier, we’re using Loki as the log backend and Grafana for visualizing the logs. To deploy these two tools, I’ll use a Docker Compose configuration.
services:
grafana:
container_name: grafana
image: grafana/grafana:10.2.4
depends_on:
- "loki"
user: root
ports:
- 3000:3000
volumes:
- grafanadata:/var/lib/grafana:rw
networks:
- log_net
restart: always
loki:
image: grafana/loki:latest
volumes:
- lokidata:/loki
container_name: loki
ports:
- "3101:3100"
networks:
- log_net
restart: always
volumes:
grafanadata:
lokidata:
networks:
log_net:
Now that Grafana is running on port 3000, let’s connect it to Loki. In Grafana, navigate to Connections > Datasources > Add New Connection. Choose Loki as the data source and provide the Loki address to complete the setup.

After saving the configuration, open the Explore tab in Grafana. As you’ll notice, the logs are currently empty. This is because we haven’t started collecting logs from the cluster yet. To address this, we need to deploy OpenTelemetry on our cluster to collect the logs and send them to Loki.
I used Helm along with the OpenTelemetry Helm chart to deploy the Otel Collector. Let’s take a quick look at how we can configure the Otel Collector to suit our needs.

The Otel Collector configuration consists of three major components: Receivers, Processors, and Exporters. These are fairly self-explanatory:
- Receivers: Collect data in a specific format.
- Processors: Apply transformations or enhancements to the collected data.
- Exporters: Send the processed data to your desired destination in the required format.
In our case, we’ll configure the Otel Collector to receive logs from files in JSON format, process them by adding the labels we need, and then export the logs to the Loki backend. We’ll need to add this configuration to our Otel Collector deployment.
In the Otel Helm chart, open the values.yaml file and locate the configuration section. Here’s the Otel config I’ve modified, and I’ll explain it line by line:
config:
extensions:
health_check:
endpoint: 0.0.0.0:13133
exporters:
loki:
default_labels_enabled:
exporter: false
endpoint: http://host.minikube.internal:3101/loki/api/v1/push
debug:
verbosity: detailed
processors:
resource:
attributes:
- action: insert
key: loki.resource.labels
value: k8s.cluster,stream,type
receivers:
filelog:
exclude: []
include:
- /var/log/pods/*/*/*.log
include_file_name: false
include_file_path: false
operators:
- type: json_parser
from: body
- type: add
field: resource["k8s.cluster"]
value: "minikube"
- type: move
from: attributes["stream"]
to: resource["stream"]
- type: regex_parser
parse_from: attributes["log"]
regex: '^(?:\d{4}/\d{2}/\d{2} \d{2}:\d{2}:\d{2} \[(?<log_type>INFO|ERROR)\])?'
- type: move
from: attributes["log_type"]
to: resource["type"]
- type: move
from: attributes["log"]
to: body
start_at: end
service:
extensions:
- health_check
pipelines:
logs:
exporters:
- loki
processors:
- resource
receivers:
- filelogLet’s start with the receiver section. Here, we’re using the filelog receiver, which allows us to collect logs from files. The include parameter specifies the file formats that the collector should scan for logs. Since we don’t want to store the filepath or filename of the log files, we set include_file_name and include_file_path to false.
Next, we have operators. These operators help us parse and extract the data we need from the logs. Since we know the log format is JSON, we’ve added a json_parser to the body field of each log instance. This ensures that the log data is correctly parsed as JSON for further processing.
Next, I added a static label named k8s_cluster. This can be useful if we want to collect logs from different clusters and need a way to filter logs between them later. The static label helps ensure that each log entry is associated with the correct cluster for easier filtering and analysis.
As we know, our application log format looks something like this:
2025/01/02 13:13:49 [ERROR] Success: User login was successful.
2025/01/02 13:13:52 [INFO] Error: Unexpected end of input.
2025/01/02 13:13:53 [INFO] Error: Unexpected end of input.
2025/01/02 13:13:55 [ERROR] Error: Unable to connect to the database.
2025/01/02 13:13:56 [ERROR] Error: Unable to connect to the database.
2025/01/02 13:13:59 [INFO] Operation completed successfully!I want to extract the log type (e.g., INFO or ERROR) and label the logs accordingly, so we can filter them later in Loki. To achieve this, I added a regex_parser to extract the log_type field. Then, I used the move operator to move the field value into the log attributes for easier access and filtering.
The last parameter is start_at. This field instructs the collector to start reading new lines from the log files and ignore any older lines that have already been processed. This ensures that we only process the most recent logs, avoiding unnecessary reprocessing of older entries.
The next section is exporters, which is quite simple. Here, I added Loki as the exporter since OpenTelemetry supports Loki. I specified the Loki push API URL for the exporter. Additionally, I disabled the default labels so I could add my own custom labels to the logs.
Now, let's move on to the processor section. In Loki, labels are stored under the log attribute section with the key loki.resource.labels. To ensure that our extracted log attributes are included in this section, we used the resource processor. This processor allows us to add attributes with values extracted from the logs, ensuring they are correctly labeled for export to Loki.
The last part of the configuration is the pipeline. In this section, we define the flow for each data type, specifying which receiver, processor, and exporter it should pass through. In our case, the logs are routed through the filelog receiver, processed by the resources processor, and then exported to Loki using the loki exporter.
Next, we need the Otel Collector to access the log directories on the Kubernetes node. To do this, we add volumes and volume mounts inside the values.yaml file. This will mount the log directories into the Otel Collector container, allowing it to access the logs for processing and export.
extraVolumes:
- name: varlogpods
hostPath:
path: /var/log/pods
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
extraVolumeMounts:
- name: varlogpods
mountPath: /var/log/pods
readOnly: true
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: trueNow that everything is configured, we just need to create a namespace for the Otel Collector and deploy it using Helm. Once deployed, it will begin collecting logs, processing them, and exporting them to Loki, where you can visualize and filter them in Grafana.
kubectl create ns otel
helm install otel -n otel .Now, if we open the Explore page in Grafana, we should be able to see our logs flowing in!
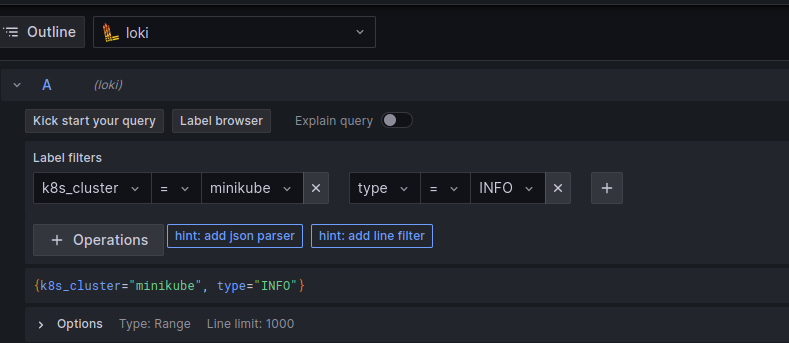
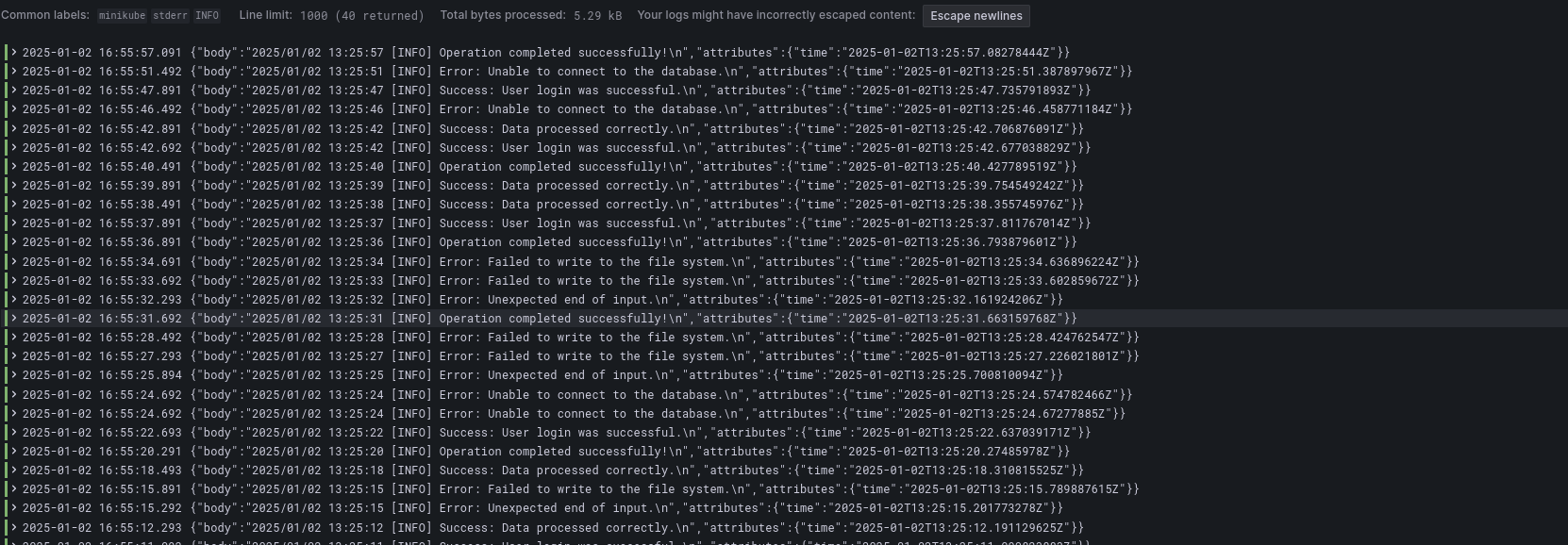
Conclusion
This use case was a simple demonstration of how powerful OpenTelemetry can be. The Otel Collector offers several key benefits for log management, making it an excellent tool for observability. One of the standout features is its flexibility. The Collector provides an easy way to collect, process, and export logs, enabling you to streamline your log pipeline without needing to rely on multiple, separate tools. With components like the filelog receiver, you can seamlessly collect logs from files, and using the Loki exporter, you can send those logs to Loki for storage and visualization.
The real power of Otel Collector lies in its processing capabilities. The built-in operators allow you to parse, transform, and enrich logs in real-time. For example, we can extract specific data from log bodies, add meaningful labels, or even drop unnecessary information—all without having to modify the source application. This makes the Otel Collector a central hub for all your log management needs.
Moreover, one of the biggest advantages of using Otel Collector is its scalability and extensibility. Since it's part of the OpenTelemetry project, it's designed to be cloud-native and can be easily integrated into a microservices architecture. Whether you're collecting logs from Kubernetes, virtual machines, or any other environment, Otel Collector can be configured to handle diverse use cases.
Additionally, if you decide to change your backend, like switching from Loki to Elasticsearch or another log storage system, you don’t need to overhaul your entire observability setup. You simply need to update the exporter in your configuration, and Otel Collector will handle the rest. This modularity allows you to adapt to different tools and backends with minimal friction, making it an incredibly flexible solution for growing observability requirements.
I hope this was helpful, and I'm excited to continue exploring new things and uncovering other cool use cases of OpenTelemetry. Feel free to reach out if you have any questions or would like to discuss more—I'm always happy to learn and share knowledge with the community!